

Introdução
No regime de grandes dados atual, é difícil acomodar todos os dados em um único CPU. Nesse caso, recorre-se a vários trabalhadores (CPUs) para lidar com os dados. Mesmo com a nuvem, configurar a infraestrutura pode ser bastante doloroso e ter isso automatizado pode economizar muito tempo e tornar o processo muito mais reproduzível.
Neste post do blog, usaremos o dstack para construir um pipeline para treinamento contínuo na nuvem usando várias GPUs.
Uma vez que você defina seus fluxos de trabalho e suas necessidades de infraestrutura com o código, poderá executá-lo rapidamente a qualquer momento e o dstack provisionará automaticamente toda a infraestrutura necessária na nuvem configurada.
Ao mesmo tempo, ele irá rastrear todo o código, parâmetros e saídas. Para fazer isso, nós usaremos as seguintes ferramentas:
- PyTorch DDP,
- PyTorch Lightning,
- dstack,
- WandB.
Deixe-me explicar brevemente o que essas ferramentas fazem.
PyTorch DDP: DDP significa “Distributed Data-Parallel”. A ideia por trás disso é que o modelo é replicado em cada trabalhador, enquanto cada trabalhador de réplica em um conjunto diferente de amostras de dados, o que possibilita a escalabilidade.
Além disso, os gradientes envolvidos são calculados independentemente em cada trabalhador para depois se acumularem através da comunicação entre eles.
PyTorch Lightning: A principal vantagem do PyTorch Lightning em comparação ao PyTorch é que não há necessidade de escrever muito código de base.
dstack: O dstack é um framework para automatizar pipelines de aprendizado de máquina. Em particular, o usuário pode definir fluxos de trabalho e seus detalhes, como um provedor de fluxo de trabalho (um programa que executa seu fluxo de trabalho), um script para executar, artefatos de entrada e saída (por exemplo, outros fluxos de trabalho em que o fluxo de trabalho atual depende e as pastas com arquivos de saída), recursos necessários (como a quantidade de memória ou o número de GPU) etc. via arquivos de configuração declarativos. Uma vez definido, os fluxos de trabalho podem ser executados via CLI do dstack. O dstack cuida da provisionamento dos recursos necessários usando uma das nuvens vinculadas (como AWS, GCP ou Azure). As execuções enviadas podem ser monitoradas na interface do usuário do dstack.
WandB: WandB é ótimo para acompanhar várias métricas, incluindo precisão, perda de treinamento, perda de validação, utilização de GPUs, memória, etc.
Agora que entendemos as ferramentas envolvidas, vamos dar uma olhada nos passos necessários para construir nosso pipeline.
Passos
Configuração do Dstack
Depois de fazer o login na sua conta no dstack.ai, clique na guia Configurações no lado esquerdo e, em seguida, clique na guia AWS.
Aqui, você deve fornecer suas credenciais da AWS e especificar quais tipos de instâncias da AWS o dstack pode usar.
Uma vez que são necessárias múltiplas GPUs para o nosso fluxo de trabalho, podemos querer adicionar um tipo de instância. Certifique-se de selecionar a região onde você tem cotações de GPU para usar esse tipo de instância.
p3.8xlarge
Para adicionar tipos de instâncias permitidas, clique no botão. Depois que você terminar, a interface do usuário deve parecer com a imagem fornecida abaixo.
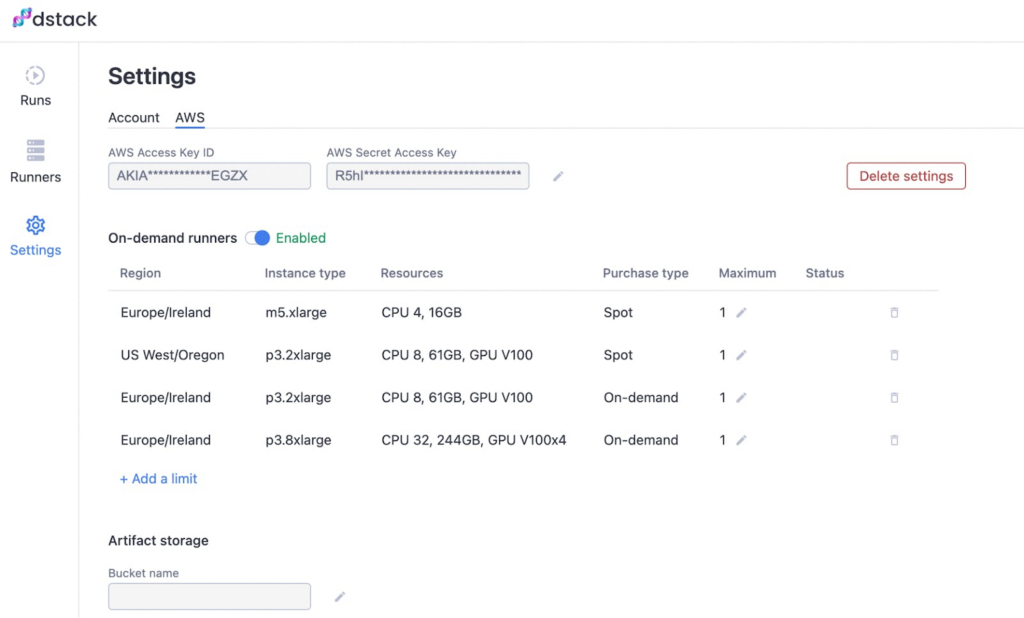
Mantenha a interface do dstack aberta, pois continuaremos voltando para ver o progresso dos nossos fluxos de trabalho em execução.
Configuração do WandB
Como vamos usar o Wandb, precisaremos especificar nossa chave API WandB como um segredo nas configurações do dstack. Sua chave API WandB pode ser encontrada em “Configurações” como mostrado abaixo.
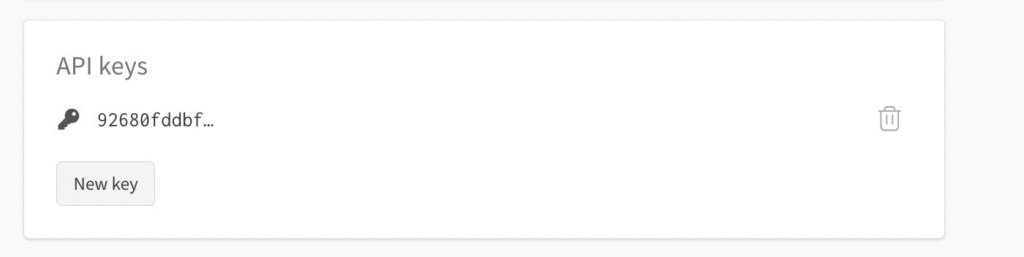
Copie a chave de API apropriada e adicione-a como um segredo nas Configurações da sua conta dstack.
Clique no botão “Adicionar segredo” e defina a chave para WANDB_API_KEY e no campo de valor cole sua chave de API WandB que você copiou anteriormente. Finalmente, suas Configurações do dstack devem parecer abaixo:
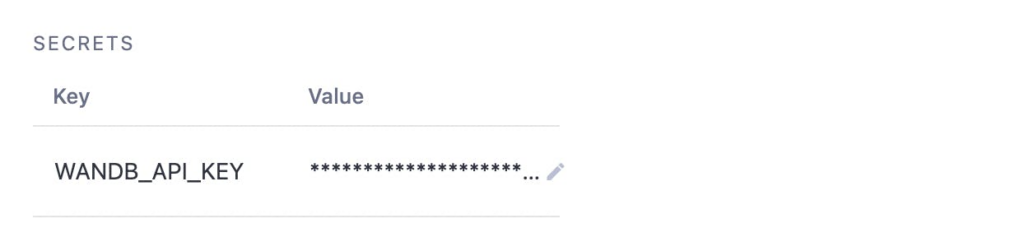
Instale os Pacotes Necessários
Aqui está o arquivo que vamos usar em nosso projeto:
requirements.txt
dstack
pytorch-lightning
torch
torchvision
wandbVá em frente e instale-o usando o seguinte comando:
pip install -r requirements.txtAgora, todos os pacotes necessários foram instalados, incluindo o CLI do dstack.
Estrutura de Diretório
Para o projeto, temos que seguir a estrutura de diretório fornecida abaixo:
<project folder>/
.dstack/
workflows.yaml
train.py
requirements.txtModelo e Treinador
O arquivo manipula os objetos do modelo e do treinador da pipeline de treinamento de aprendizado de máquina.
train.pyDependendo do número de GPUs no dispositivo (que pode ser verificado via ), precisamos definir os argumentos do objeto treinador de forma apropriada.
torch.cuda.is_available()Para a CPU, precisamos definir e para o restante dos casos, definimos , o que fazemos através da variável.
accelerator = 'cpu' accelerator = 'gpu'accelerator_name
# trainer instance with appropriate settings
trainer = pl.Trainer(accelerator=accelerator_name,
limit_train_batches=0.5,
max_epochs=10,
logger=wandb_logger,
devices=num_devices,
strategy="ddp")Para garantir que o Pytorch Lightning se baseia na estratégia de treinamento DDP mencionada anteriormente na Introdução deste blog.
strategy="ddp"Também configuramos o objeto para usar o WandB para rastrear as métricas e outras informações do sistema.
logger=wandb_loggerpl.TrainerO código completo deste tutorial pode ser encontrado aqui.
Fluxos de trabalho do dstack
Agora, especificamos o fluxo de trabalho através do arquivo. O conteúdo do arquivo é o seguinte:
.dstack/workflows.yaml.dstack/workflows.yamlworkflows:
- name: train-mnist-multi-gpu
provider: python
version: 3.9
requirements: requirements.txt
script: train.py
artifacts:
- data
- model
resources:
gpu: 4Execuções dstack
Para executar o fluxo de trabalho, tudo o que precisamos fazer é executar o seguinte comando no terminal.
dstack run train-mnist-multi-gpuAgora, abra dstack.ai para fazer o login e ver os fluxos de trabalho. Você verá o conteúdo da guia “Corridas” como abaixo.

Você pode clicar em Executar para ver o progresso do fluxo de trabalho. Na guia “Logs”, você verá o servidor na nuvem executando o train.py após alguns minutos de iniciar o trabalho.
Na guia “Jobs”, você verá informações como abaixo.
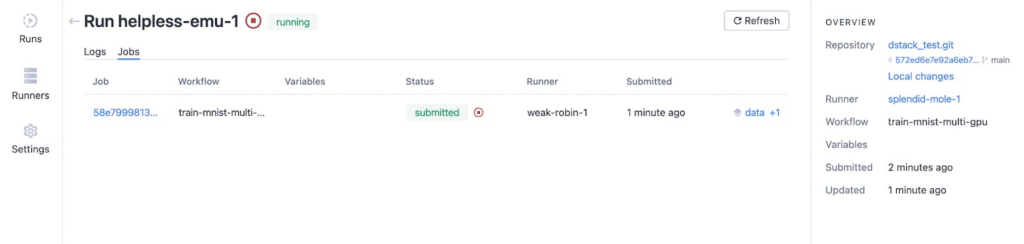
Depois que a execução acabar, podemos monitorar os artefatos clicando no botão “dados + 1” e a saída parece abaixo depois de clicar nas pastas “dados” e “modelo”.
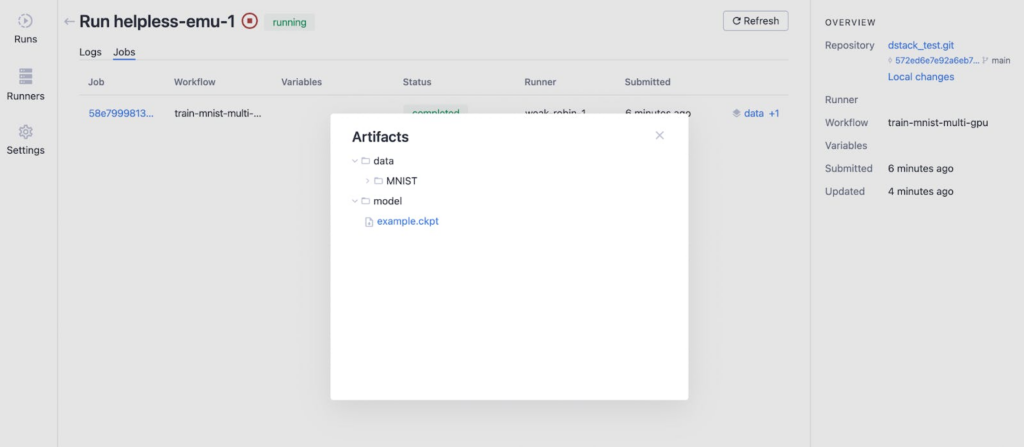
É possível fazer o download dos conteúdos dos artefatos via CLI do Dstack.
Na aba “Runners” do lado esquerdo, você encontrará informações sobre as instâncias específicas sendo usadas.
Monitoramento do WandB
Depois que a execução for concluída, você encontrará nas WandB as métricas que você acompanhou. Você também encontrará informações sobre a utilização da GPU e vários outros detalhes cruciais.
Em princípio, você pode usar qualquer outro serviço de rastreamento de experimentos junto com o dstack.
Conclusão
Espero que você tenha gostado de ler este blog.
O código usado neste post do blog pode ser encontrado no repositório git aqui.
As referências que usei são as seguintes.

