

Quanto comecei minha jornada de aprendizado na área de programação e desenvolvimento web não dei muita importância para o que era o HTTP e como ele funcionava. De forma similar quando o HTTP/2 começou a aparecer eu ainda não compreendia exatamente como ele seria útil.
Hoje, depois de alguns anos lidando com a criação de website, sei que tem alguns conhecimentos que fazem uma falta imensa se ignoramos. Um desses conhecimentos é como funciona os protocolos HTTP e HTTP2. Aproveito para deixar aqui um outro artigo complementar que explica a diferença entre URL, URI e URN.
Também recomendo nosso artigo sobre como se tornar um desenvolvedor web se você está começando ou buscando se especializar em alguma área de programação para a web.
Nesse artigo vou explicar o que é o HTTP, qual é a função desse protocolo e também como lidar com ele do ponto de vista mais técnico. Aproveito para deixar crédito a algumas imagens da Mariko Kosaka que vou utilizar pois achei sensacionais.
O que é HTTP
A abreviação HTTP vem do Inglês Hypertext Transfer Protocol e é a principal forma de recebimento e envio de informações na internet. Esse protocolo nada mais é do que o método de troca de informações entre usuários e servidores. Utilizando termos mais usados e técnicos, temos de um lado o Cliente e do outro o Servidor.
Cliente
O Cliente – também conhecido por user agent – é qualquer aparelho, dispositivo, navegador, que faz uma requisição de algum recurso para o servidor. Essa requisição é transmitida pela internet como um pacote de informações para um determinado endereço URL (sugiro ler o artigo mencionado acima sobre diferença entre URL, URN e URI).
Esse pacote enviado do cliente para o servidor contém uma parte chamada Headers (cabeçalhos). Nela temos uma série de opções de como a transação e uso das informações devem ser consideradas e trabalhadas. Alguns exemplos mais comuns são o de autenticação. cookies, segurança e cache. Uma dica fácil aqui é que todo header consiste de uma chave e um valor, igual quando escrevemos um objeto em JSON.
chave: valor
Servidor
Do outro lado temos o servidor que é uma máquina física em algum lugar no mundo cujo endereço de destino é aquele que acompanha a requisição. Para saber como a conexão de fato chega até esse endereço sugiro da uma aprofundada em como o DNS funciona.
Recursos
Existem diversos recursos que podemos utilizar para simular requisições entre clientes e um servidor e também visualizer todas as informações e headers desse pacote. Vou listar abaixo alguns mais simples e também outro que acredito ser o recomendado como uma ferramenta importante no desenvolvimento de APIs e, no fundo, de qualquer website.
- [HTTP Debugger]()
- API Tester
- [Postman]()
O Postman na minha opinião é o melhor recurso para testar requisições e pode ser utilizado tanto com websites em servidores de produção/desenvolvimento quanto em servidores locais – localhost.
Exemplo
Para ilustrar vamos fazer uma requisição do tipo GET para esse website da Iglu. Mais à frente explico os tipos de requisições, mas em geral a requisição do tipo GET é usada quando estamos pedindo algo do servidor como clientes.
Requisição:
Headers:
GET / HTTP/1.1
Host: www.igluonline.com
Accept: \*/\*
User-Agent: Rigor API TesterÉ legal observar a estrutura que mencione acima de chave: valor e os nomes das chaves. A primeira linha é a indicação do tipo de requisição e a versão do HTTP – vamos ver mais abaixo a versão HTTP/2.
Resposta:
Headers:
HTTP/1.1 200 OK
Cache-Control: public, max-age=0, must-revalidate
Content-Type: text/html; charset=UTF-8
Date: Fri, 08 Jun 2018 19:44:23 GMT
Etag: "75e8ff38b255084f900182acc1f26192-ssl"
Strict-Transport-Security: max-age=31536000
X-Bb-Deploy-Id: 5b1abca711b73b1882345ab9
Age: 0
Transfer-Encoding: chunked
Connection: keep-alive
Server: NetlifyResponse body:
html do site todo aqui
Como funciona o HTTP
Agora que já entendemos um pouco o que é o HTTP vamos aproveitar as ilustrações abaixo e contar o passo a passo de uma requisição. As imagens estão em Inglês, já que foram feitas pela Mariko Kosakacomo mencionei, mas explico com detalhes abaixo.
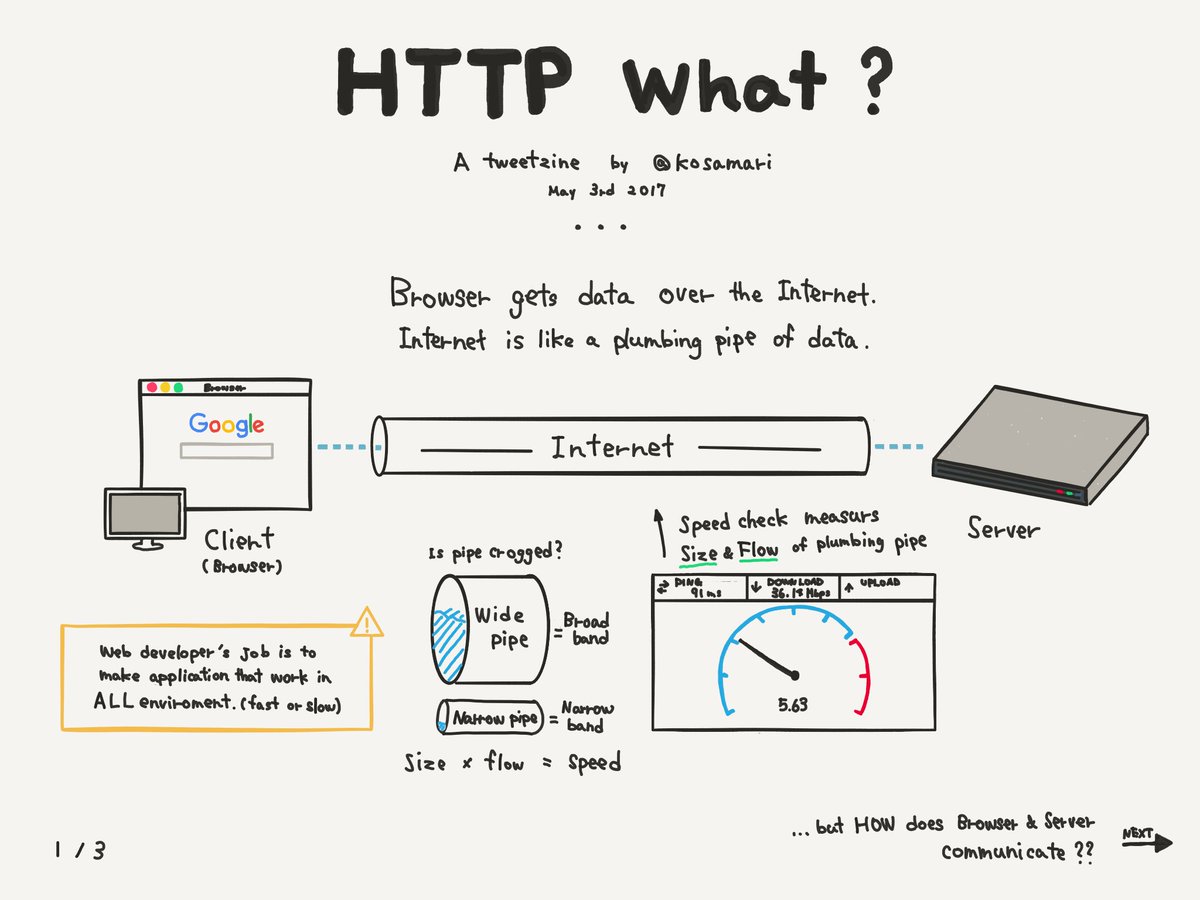
Vou usar de exemplo um usuário, vamos chamá-lo de João, entrando no site da Iglu já que tivemos a ideia ali em cima de como ficam os headers no GET.
Usuário chega ao site
João entrou no seu computador, abriu o Google Chrome e digitou www.igluonline.com. As informações sobre João foram até o servidor através da internet – lembrando que aqui tem todo um detalhamento de como um endereço chega até um local físico no mundo para puxar o site e isso tem a ver com o DNS que não vamos entrar em detalhes aqui.
Chegando no servidor nossos programas fazem o que precisam para gerar um HTML que possa ser enviado para o navegador. Esse código então é enviado no corpo da resposta do servidor juntamente com vários headers explicando como o navegador deve processar e o que fazer em seguida (como salvar arquivos como cache).
O navegador vai então utilizar as informações que vieram na resposta dessa comunicação HTTP e carregar o corpo do pacote: o HTML.
Algo que é bem interessante no desenho é que mostra alguns pontos referentes à velocidade de carregamento. O canal de comunicação da internet, por onde passam os pacotes da requisição HTTP, influencia diretamente na quantidade de informação é possível enviar e receber de uma vez. Se é um largo chamamos de “banda larga”.
Uma colocação legal da imagem também é que o trabalho de desenvolvedores web é fazer com que nossas aplicações consigam ser carregadas em qualquer tipo de conexão: lenta ou rápida. E aí que a quantidade de imagens, scripts, arquivos de CSS e JavaScript que colocamos entra em jogo.
O site começa a carregar
Na hora que o HTML enviado no corpo da requisição HTTP começa a ser interpretado, o navegador descobre que existem vários recursos ali que precisam ser adquiridos. Nesse momento ele começa a fazer requisições de busca desses recursos em múltiplos destinos.
Para cada imagem, arquivo CSS, arquivo JS, documento e outros o navegador faz uma nova chamada para buscar. É por isso que é super importante ter cuidado com a quantidade de recursos que adicionamos ao nosso site uma vez que demorará mais para ser carregado. Uma dica interessante aqui é a distinção entre requisições síncronas vs assíncronas. No primeiro caso o navegador respeita a ordem e espera uma requisição retornar para então passar para a próxima. Já no segundo caso o browser faz requisições em paralelo. Cada jeito tem seu propósito, mas em muitos casos podemos agilizar o carregamento utilizando o assíncrono – async.
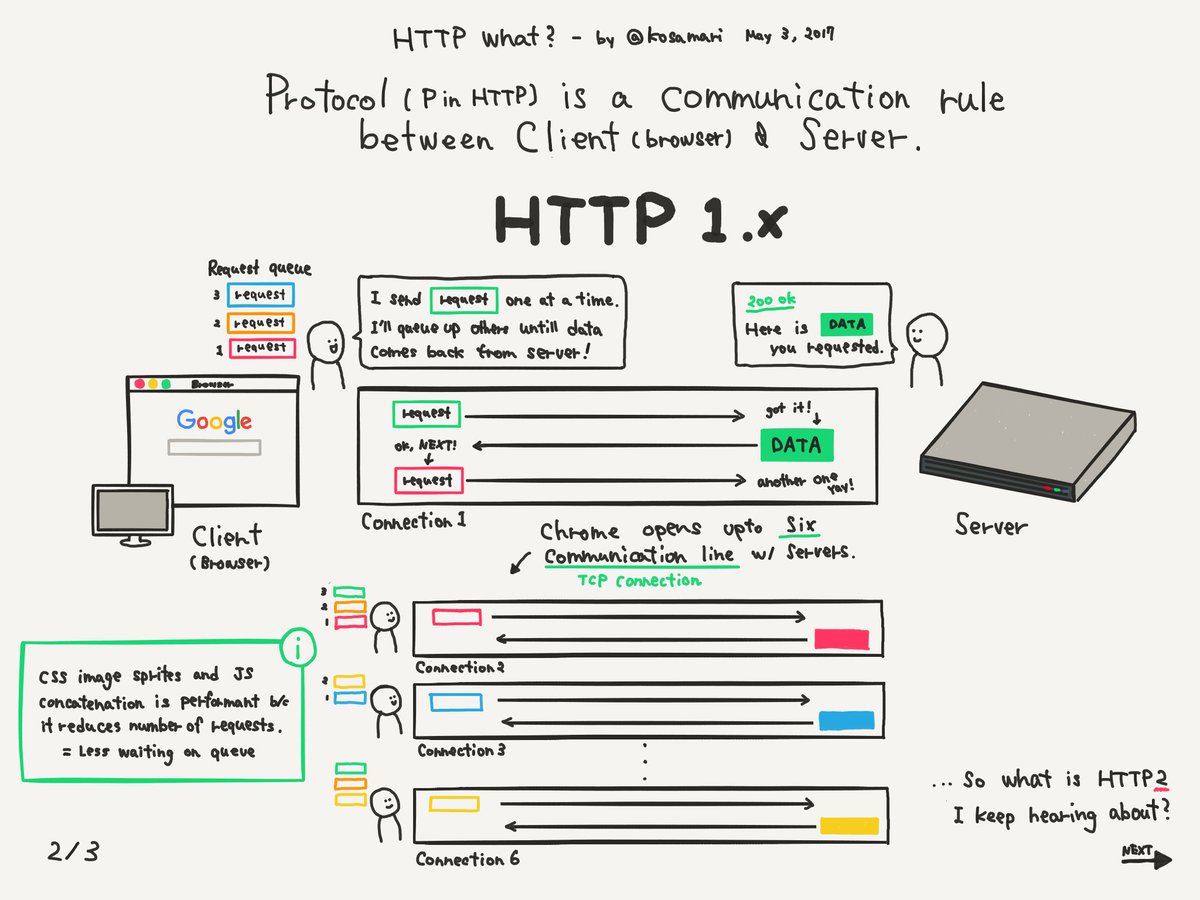
Nessa imagem podemos ver exatamente esse processo do usuário “pedir” o site e o servidor entregando as suas partes. Algo interessante mencionado é que o Google Chrome consegue abrir até 6 conexões simultâneas para carregar os arquivos e informações necessárias.
Ao final desso processo todo você é capaz de ver uma página cheia de interações, textos, imagens, fontes e cores como essa.
Qual a diferença entre HTTP 1.1 e HTTP/2?
A ideia do HTTP/2 começou em 2014 com uma apresentação de um cara chamado Daniel Stenbergtrazendo várias melhorias com relação à sua versão vigente.
As principais são:
Fluxos multiplexados
Aqui o grande avanço vem relacionado novamente com o carregamento assíncrono de recursos. Através de uma mesma conexão os navegadores são capazes de requerer vários arquivos de tipos diferentes em paralelo.
Server Push
Esse nome tem sido popular entre alguns desenvolvedores web e basicamente aponta para uma funcionalidade muito legal que o HTTP/2 trás. Como vimos acima, no HTTP 1.1 o navegador precisa primeiro ler toda o HTML da sua página para determinar quais são os arquivos que ele terá que requerer posteriormente. Já no HTTP/2 o servidor pode mandar arquivos mesmo sem o navegador pedir.
O mais legal disso é que não há problemas de segurança envolvidos ao contrário do que parece quando falamos que o servidor pode enviar o que ele quiser para nossos computadores. No caso do HTTP/2 o servidor apenas envia os arquivos como uma forma de agilizar e parte de uma conexão já pre-estabelecida entre cliente e servidor. As requisições sempre partem do cliente e quando seu navegador pede os arquivos eles já estão prontos para serem usados ao invés de ter que ir até o servidor de novo e buscar.
Headers HPACK
Apesar das informações dos headers serem pequenas, são bilhões de requisições que os servidores lidam diariamente. Pensando nisso os headers no HTTP/2 são compactados nesse novo formato para dar mais velocidade e otimização.
Prioridades e dependências
Uma funcionalidade bem legal do HTTP/2 é você poder determinar quais dependências e arquivos são mais importantes e devem ser priorizados nas requisições. Isso pode ser bem útil quando você tem uma página, por exemplo, cheia de imagens mas quer que as imagens do topo sejam carregadas antes das demais para dar a melhor experiência para o usuário.
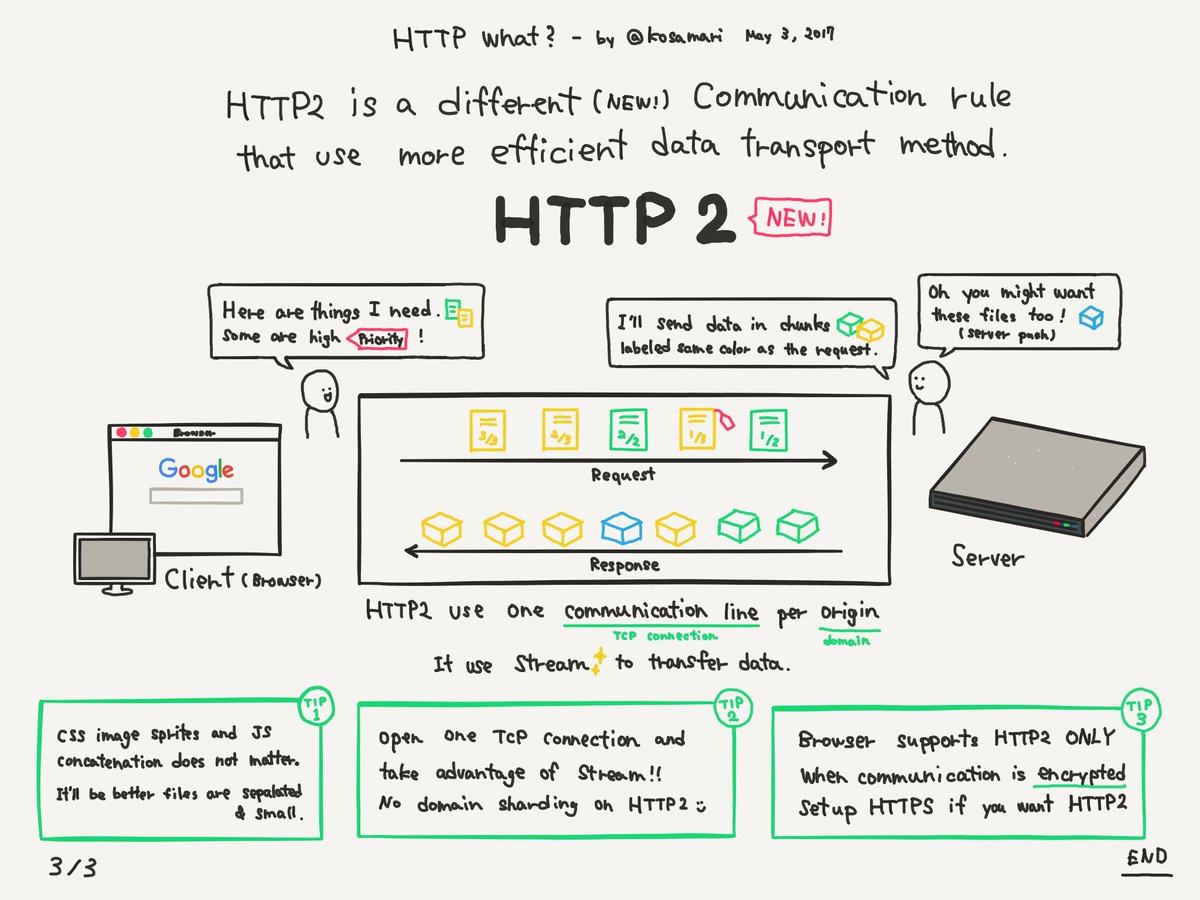
Aproveitando as dicas da imagem podemos pensar no que isso significa para o jeito que hoje criamos código. Como agora não importa tanto a quantidade de recursos para a velocidade do site, não precisamos mais concatenar vários arquivos JavaScript ou CSS. Fazer sprites de imagens que é uma prática corrente em aplicações maiores também não é mais necessário.
Outra questão importante do HTTP/2 é que ele só aceita conexão segura e encriptada. Então para você poder desfrutar desses benefícios terá que utilizar um certificado SSL – HTTPS.
O que é o certificado de segurança HTTPS
De forma simples, o “S” ao final de HTTPS significa secure – seguro em Português. Isso significa que a conexão é segura entre o cliente o servidor, enquanto o HTTP normal não é seguro. Mas o que significa segurança?
Uma conexão é segura quando ela é encriptada. No caso do protocolo HTTP essa encriptação é feita através de um certificado de segurança chamado SSL – Secure Socket Layer.
A transição de HTTP para HTTPS é um processo super importante pois garante que as informações que passam pela “internet”, como vimos acima, não estão legíveis para qualquer um que possa interceptar a conexão.
Especialmente para websites que lidam com informações sensitivas dos usuários, como cartão de crédito, informações pessoais e outros, ter uma conexão segura é obrigatório. Por isso inclusive que o HTTP/2 já tem como padrão e obrigatório o uso de HTTPS para funcionar.
Inclusive, o próprio Google valoriza mais websites que possuem o certificado SSL instalado em seus websites no ranqueamento.
Métodos HTTP
Os métodos de comunicação HTTP, comumente chamados de verbos, nada mais são do que uma ação específica que você deseja que a operação requisitada pelo cliente realize no servidor. Essa questão está muito próxima de conceitos como REST, que já há algum tempo fazem parte de princípios que todo desenvolvedor web precisa aprender. Sugiro esses dois artigos abaixo para explorar mais essa área:
Existem 8 verbos usados mas principalmente 4 métodos temos que conhecer:
- GET – Esse método conhecemos acima quando chamamos o site da Iglu. Ele serve para requisitar algo do servidor. Esse algo sendo imagens, arquivos, etc. Podemos dizer que ele é um método seguro e não devemos utilizar ele para fazer qualquer ação no servidor. Por exemplo não vamos utilizar ele para atualizar uma informação de um usuário.
- POST – Ao contrário do GET, o POST envia um corpo junto com os headers. Nesse
bodyenviamos informações para a criação de um novo recurso no servidor. Dois exemplos comuns são a criação de um novo usuário ou envio de um formulário de contato. Ele também é muito útil para realizar ações não relacionadas com a requisição mas precisam ser executadas por algum motivo no servidor. Um exemplo aqui é de disparar um e-mail para determinado usuário depois que ele atinge um determinado número de páginas vistas no site. - PUT – Se no GET não podíamos atualizar um usuário aqui no PUT é exatamente o que fazemos. Algo interessante, aproveitando o exemplo, é que caso não exista um usuário ele também pode criar um. O PUT e o POST são bem parecidos, mas é interessante pelo jeito REST separarmos as ações de acordo com o que cada um faz como ponto principal.
- DELETE – Nesse último caso podemos utilizar para remover algum recurso. No caso do usuário poderíamos deletar ele de nossa base usando uma requisição DELETE.
Para exemplo, alguns outros métodos são: HEAD, OPTIONS, TRACE, CONNECT.
Status da resposta do servidor à requisição HTTP
Quando o cliente faz uma requisição o servidor deve fazer seu processamento e enviar as informações de volta. Mas e se não há informações para enviar? Ou se o servidor estiver fora do ar? Ou se for uma página inválida? Existem várias possibilidades de sucesso e de problemas que podem acontecer quando essa conexão entre cliente e servidor é estabelecida.
Para isso, existe uma resposta de três números chamada status que o servidor envia junto com o header. São dezenas de status possíveis, mas aqui vamos passar pelos principais. Uma dica interessante é que os status estão categorizados de acordo com o primeiro número.
- 1XX – Respostas informativas
- 2XX – Respostas de sucesso
- 3XX – Redirecionamentos
- 4XX – Erro na resposta para o cliente
- 5XX – Erro no servidor
Vamos então às principais:
Resposta status 200 – OK
Significa que a reposta do servidor foi bem sucedida.
Resposta status 301 – Redirecionamento permanente
O recurso foi movido permanentemente para outro local. É muito comum ser utilizado para mudança de endereço de páginas ou domínios. Por exemplo há um ano mais ou menos mudamos o endereço do blog da Iglu de blog.igluonline.com para igluonline.com. Na ocasião realizei um redirecionamento permanente 301 de todas as páginas do site para o novo domínio.
Resposta status 302 – Encontrado
Apesar do nome ser “encontrado” o status 302 é similar ao 301 e podemos até chamá-lo de redirecionamento temporário. Significa que o recurso foi encontrado mas está temporariamente em outro endereço (ou em outra URI para sermos mais técnicos).
Algo interessante para mencionar é que se você utilizar o 301 o Google entenderá que o novo destino é aquele e atualizará com certa velocidade o índice. Já no 302 ele não vai fazer isso. Então sempre que fizer redirecionamentos é legal prestar atenção para ter o resultado desejado.
Resposta status 401 – Não autorizado
O endereço especificado exige algum tipo de autenticação do usuário tentando acessar o recurso. É possível fazer a autenticação.
Resposta status 403 – Proibido
Essa resposta acontece quando o cliente não tem os direitos de acessar aquele recurso e o servidor se recusa a completar a requisição.
Resposta status 404 – Não encontrado
Esse é um dos erros mais comuns e conhecidos até por leigos. Ele acontece quando o cliente tenta acessar um recurso que não foi encontrado pelo servidor, então ele não conseguiu enviá-lo.
Resposta status 500 – Erro interno do servidor
Esse erro acontece quando o servidor encontra uma situação que ele não sabe lidar. É comum esse erro acontecer quando a aplicação está com algum erro.
Resposta status 502 – Bad Gateway
O status 502 em geral indica que há algum problema na própria conexão entre o cliente o servidor. Seja o servidor agindo como proxy ou gateway.
Resposta status 503 – Serviço indisponível
O status 503 significa que o servidor não está pronto para atender à requisição. Em geral significa que o servidor está desligado, indisponível, em manutenção ou mesmo sob muito estresse.
Próximos passos
Nesse longo artigo passamos por o que é HTTP, como ele funciona, qual a sua diferença para o HTTP/2 e também para o HTTPS. Além disso vimos algumas características como status de resposta e métodos.
Esse é um conteúdo bastante denso e conseguimos ir até bem mais fundo em alguns elementos. Mas acho bastante importante para todo desenvolvedor web entender essa dinâmica de “conversa” entre o cliente e o servidor. Além disso, conhecer os termos e como eles se relacionam ajuda demais na hora de buscar soluções na web e falar a mesma língua dos outros programadores.
Se você curtiu esse assunto aproveita para deixar um comentário e compartilhar com seus amigos desenvolvedores para que possamos ter uma comunidade cada vez mais engajada de profissionais sensacionais.
Divirta-se!

